Chapter 7: Dynamic Data on the World-Wide Web
7.2 Building Dynamic Web Pages
Every piece of a Web page is fully programmable with JavaScript, using the Document Object Model and a set of properties and methods called an application programming interface (API).
Programming libraries like the open-source jQuery make this even easier by collecting together common activities in easy-to-use functions that hide the complexities of browser inconsistencies.
The Mozilla Foundation, again, provides a good reference for the DOM API.
The Document Object Model
The DOM Library jQuery
The Document Object Model
When a Web browser loads an HTML document, it parses (interprets) the HTML and builds a set of programmable objects for every element and the content they enclose.
These document objects can then be directly read or written using JavaScript.
You can experiment with these objects by following along with this text, using the reference version of the document gne.html and its console.
The Document Hierarchy
As noted previously, an HTML document has a hierarchical structure, with many elements being containers of content, attributes, and other elements, collectively known as nodes.
<!DOCTYPE HTML>
<html>
<head>
<meta charset="UTF-8" />
<title>The Geography of New England</title>
<meta name="author" content="Lyman R. Allen" />
<meta name="author" content="Alonzo J. Knowlton" />
<meta name="date" content="1912">
<link href="gne.css" type="text/css" rel="stylesheet"></link>
<script src="js/mass_schools.js"></script>
</head>
<body>
<header>
<h1><a href="https://books.google.com/books?id=-DREAQAAMAAJ">The Geography of New England</a></h1>
<div id="byline">
By <span class="author">Lyman R. Allen</span>,
<span class="credentials">formerly Instructor in Geography, State Normal School, Providence, Rhode Island</span>,<br />
and <span class="author">Alonzo J. Knowlton</span>,
<span class="credentials">Superintendent of Schools, Belfast, Maine</span>.
</div>
<hr id="titleSeparator" />
</header>
<div id="maincontent">
....
</div>
</body>
</html>
In the Document Object Model (DOM) we refer to the relationships between different nodes with familial terms. For example, the <h1> element is the parent of the <a> element and an ancestor of the text node "The Geography of New England", while at the same time being a sibling of the elements <div id="byline"> and <hr id="titleSeparator" />, and a child of <header>. All of the nodes except for <!DOCTYPE HTML> are descendants of <html>, and all are descendants of the document itself:
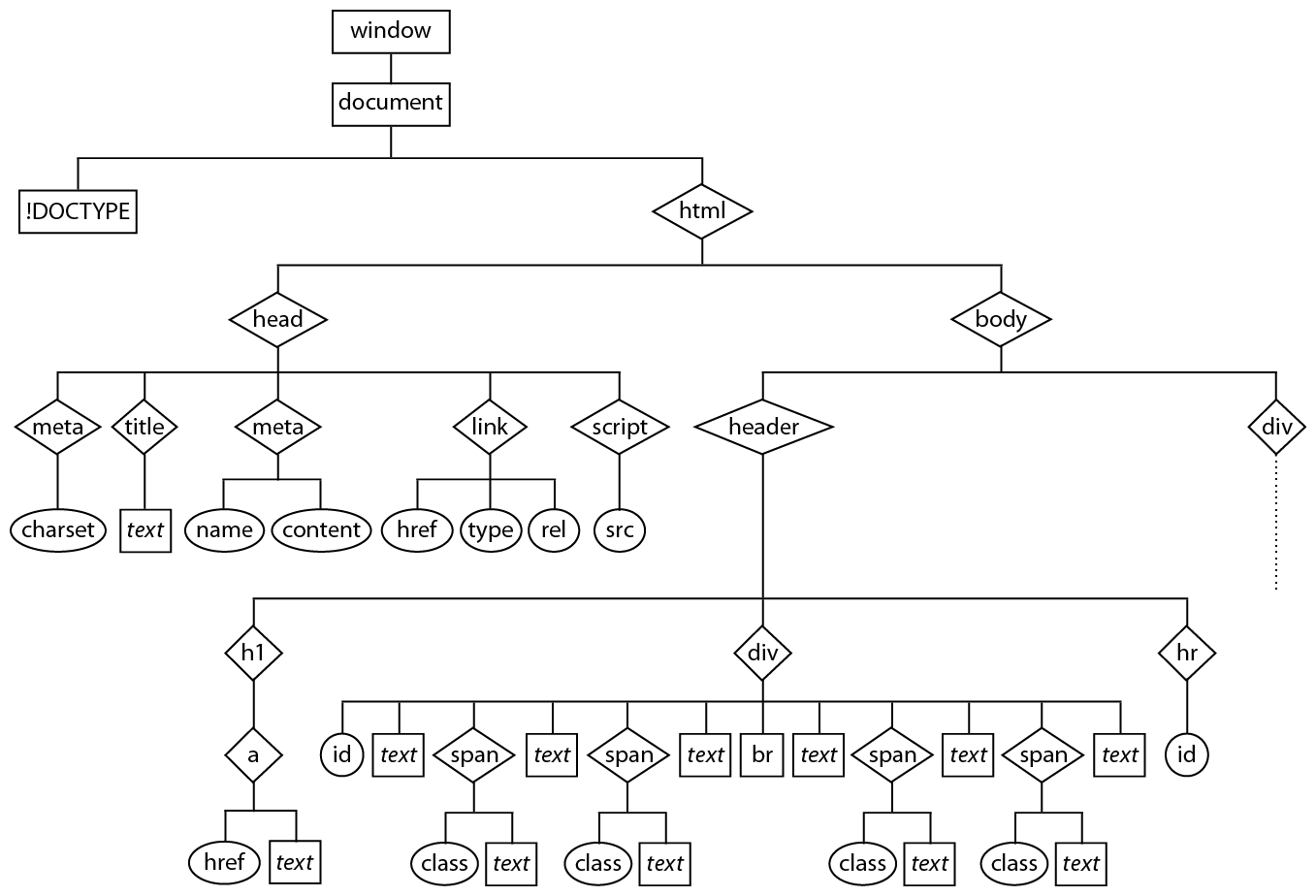
Every element in this hierarchy is an object, with a set of properties and methods that can be read and sometimes set with JavaScript. There are a few standard elements, such as <body> and <title>, that can be simply referenced, for example:
document.title // Type this into the console!
⇒ "The Geography of New England"
Most other elements must be looked up in some way, commonly by letting the document find them for you, from an index it creates as it parses the document:
byline = document.getElementById('byline')
⇒ <div id="byline">
You can obtain a lot information about an element from the properties of its representative object, for example:
byline.id
⇒ "byline"
byline.nodeType // 1: an ordinary element; 3: text; 9: the document; 10: <!DOCTYPE>
⇒ 1
byline.nodeName
⇒ "DIV"
If you know the relative location of two elements, you can also climb up and down the node tree:
header = byline.parentNode
⇒ <header>
by = byline.firstChild
⇒ #text "
By "
Note that, while in the second case by the console prints the text in the node, this property is not actually text — it’s a text object in the DOM, which the console is helpfully identifying for you by printing some common details, viz. both the node name and value:
by.nodeName
⇒ "#text"
by.nodeValue
⇒ "
By "
Note that this text value includes “return” characters, literally everything that is between the div id="byline"> tag and the <span class="author"> tag:
<div id="byline">
By <span class="author">Lyman R. Allen</span>,
<span class="credentials">formerly Instructor in Geography, State Normal School, Providence, Rhode Island</span>,<br />
and <span class="author">Alonzo J. Knowlton</span>,
<span class="credentials">Superintendent of Schools, Belfast, Maine</span>.
</div>
For any element you can request an array of its child nodes:
byline.childNodes // array of all child nodes of the byline, including by
⇒ NodeList [ #text "
By ",
<span.author>,
#text ",
",
<span.credentials>,
#text ",",
<br>,
#text "
and ",
<span.author>,
#text ",
",
<span.credentials>,
#text ".
"
]
Sometimes you must loop through these node lists and test their contents to find the right one, for example to find the text and:
for (i = 0, nodes = byline.childNodes; i < nodes.length; i++)
{
if (nodes[i].nodeType == 3 &&
nodes[i].nodeValue.indexOf('and') != -1)
/* string.indexOf(substring) returns the substring's
position within string, and -1 if not present */
{
console.log(i);
break;
}
else
continue;
console.log(-1); // Only reaches here if nothing found in loop
}
⇒ 6
In addition to searching for identified elements, you can request arrays of specific element types:
smithImg = document.getElementsByTagName('img')[1] // array of img elements in document; select second
⇒ <img alt="A group of Smith College buildings, Northampton. To the right may be seen Music Hall."
title="Fig. 128. Smith College, Northampton"
src="https://cschweik.gitbooks.io/community-service-with-web-based-gist/content/data/Dodge_s_Geography_of_New_England%2067_Fig_128.jpg"
class="rightImage"
/>
If document.getElementById(identifier) cannot find the specified identifier, it will return a null result, another data type in JavaScript that represents “nothing”. To avoid an error it is best to test for this result if you don’t know for certain that a given identifier is present:
if ((headline = document.getElementById('headline')) == null)
/* work around the absence of headline */
else
/* do something with headline */
Element Attributes
Attributes in elements can be accessed in several ways:
smithImg.title // As a property; very convenient
⇒ "Fig. 128. Smith College, Northampton"
smithImg.getAttribute('src') // With a look-up function; very general
⇒ "https://cschweik.gitbooks.io/community-service-with-web-based-gist/content/data/Dodge_s_Geography_of_New_England%2067_Fig_128.jpg"
smithImg.attributes[0].value // Knowing it's the first item in an array of attribute objects
⇒ "A group of Smith College buildings, Northampton. To the right may be seen Music Hall."
There are a number of such properties and methods available, so if you need something, look for it in the DOM API reference, you just might find it!
Modifying the DOM
Some of the document and element properties above are directly modifiable:
by = document.getElementById('byline').firstChild;
by.nodeValue = 'Written by ';
Note that the text has now changed in the web page:

Attributes can also be set this way:
smithImg = document.getElementsByTagName('img')[1];
smithImg.title;
⇒ "Fig. 128. Smith College, Northampton"
smithImg.title = 'Fig. 128. Pioneer Homestead, Noho'
⇒ "Fig. 128. Pioneer Homestead, Noho"
smithImg.style = 'width: 70%;' // Style selector will override class selector
⇒ "width: 70%;"
In addition to modifying the values of nodes and attributes, the document model itself can be modified by adding or removing nodes, using a set of predefined methods. As one example, we can create a document fragment that is a paragraph element containing some text, and then insert it into the document hierarchy at the appropriate place, whereupon it becomes visible:
publisher = document.createElement('p')
publisher.appendChild(document.createTextNode('Published by Rand, McNally & Company'))
⇒ #text "Published by Rand, McNally & Company"
titleSeparator = document.getElementById('titleSeparator');
header = titleSeparator.parentNode;
publisher = header.insertBefore(publisher, titleSeparator);
publisher.style = 'text-align: center;';
Again, there are a number of such properties and methods available, so if you need a capability, look for it. Many of them are non-standard but commonly available in browsers, e.g. innerHTML().
You may wonder, why go to all of the trouble to modify the DOM using these methods when it’s simpler to use document.write():
document.write('<div>Published by Rand, McNally & Company</div>')
One reason is that a statement like the above must be placed at a specific position in the document; if what you are writing is large, you might want to delay writing it until the page framework has displayed.
Creating the content to be placed into document.write() can also get pretty messy, and separating the text creation from that of the containing element makes your code a little cleaner when using DOM libraries such as jQuery.
Most importantly, you might want to change the page content in response to an interactive request, without reloading the entire page.
The DOM Library jQuery
The process of modifying the DOM is greatly assisted by the use of libraries of JavaScript functions such as jQuery and D3, which have become extremely popular in recent years.
jQuery is described as “a fast, small, and feature-rich JavaScript library [that] makes things like HTML document traversal and manipulation … much simpler with an easy-to-use API that works across a multitude of browsers.” The most recent version, designed for more recent browsers, weighs in at 246 KB (86 KB compressed).
D3 or “Data-Driven Documents” is described as “a JavaScript library for manipulating documents based on data [helping bring them] to life using HTML, SVG and CSS. D3’s emphasis on Web standards gives you the full capabilities of modern browsers without tying yourself to a proprietary framework, combining powerful visualization components and a data-driven approach to DOM manipulation”. It is somewhat larger than jQuery at 319 KB (144 KB compressed).
One primary advantage of these libraries is that they can hide some of the inconsistencies of different Web browsers, automatically using work-arounds when necessary.
We will only talk specifically about jQuery in this book, in particular because it forms the foundation of the Web page framework Bootstrap that we’ll see later. You may want to look into D3 for particular tasks, as it provides a set of tools for displaying data in nice ways.
Installing jQuery
You can obtain jQuery from the Web site http://jquery.com/. Get the latest, compressed, production version and install it in the same gne folder as your main document, but in a subfolder named js (a common place to put such libraries), with its pieces grouped together in another folder jquery.
The minimal (compressed) version will be faster to load because it shortens variable names and removes all unnecessary space from the library, making it smaller but also avoiding unnecessary #text node creation by your browser. It’s pretty much unreadable by humans, though.
The jQuery documentation is also available from the same site.
To use jQuery in a Web page, just place this library reference (or something similar if you’re using a different version) somewhere in the page:
<script src="js/jquery-2.2.1.min.js"></script>
It could be placed in the <head>, which would ensure that it’s loaded before it’s used, but because of its size you may prefer to place it at the end of the document (after the closing </body>), which would allow the page to first load and show at least a basic framework before it seems to pause. In any case, it’s important that the library be loaded before jQuery is first referenced.
Examining the DOM Using jQuery
jQuery is provided to your Web page as an object with many methods, and it can be referenced either with jQuery or $, a variable name that is assigned to this object for simplicity.
jQuery uses the notation of CSS selectors to find elements of interest and provides streamlined methods to operate on them. For example, instead of the previous cases where we used document.getElementById('byline') and document.getElementsByTagName('img')[1]:
byline = $('#byline') // Selects the element with this ID
smithImg = $('img').eq(1) // Selects all image elements and then the second in the list
⇒ Object { 0: <img.rightImage>, length: 1,
prevObject: Object, context: HTMLDocument → gne.html }
The result of these expressions is a jQuery selection object that contains the matched elements with numbered properties (so that it behaves like an array), along with additional information that jQuery can later reference:
authors = $('.author') // Selects all elements with the class="author"
⇒ Object { 0: <span.author>, 1: <span.author>, length: 2,
prevObject: Object, context: HTMLDocument → gne.html, selector: ".author" }
authors[0] // Returns just the first element
⇒ <span.author>
Once you’ve created a jQuery selection you can keep using the API, e.g. to determine an element’s text content:
authors.eq(0).text()
⇒ "Lyman R. Allen"
Or determine a particular attribute’s value:
smithImg.attr('title')
⇒ "Fig. 128. Smith College, Northampton"
Finding particular nodes is simplified, similar to using Array.forEach() where a callback function is passed to a filter that applies it to each item selected:
byline.contents().filter(
function(index, element) {
return element.nodeType == 3 && element.nodeValue.indexOf('and') != -1;
}
)
⇒ Object { 0: #text "
and ", length: 1, prevObject: Object, context: HTMLDocument → gne.html }
Notice the chaining of methods together here, the result of each method is passed on to the next, which works as long as they produce an object with the same format.
Modifying the DOM Using jQuery
To set an attribute, use the attr() method again, but with a second argument, the new value:
smithImg.attr('title', 'Fig. 128. Pioneer Homestead, Noho')
smithImg.attr('title')
⇒ "Fig. 128. Pioneer Homestead, Noho"
Finally, inserting elements into the DOM is much easier, using the notation $('<p>') to create an unattached element in the DOM with a certain style and content, and another jQuery method to insert it in place:
publisher = $('<p>').text('Published by Rand, McNally & Company')
.css('text-align', 'center');
$('#titleSeparator').before(publisher)
As one more example, here’s how the Massachusetts JSON data we saw previously can be written out with jQuery. Starting with just the <table> and <thead> portions, jQuery can append the rest:
<table>
<caption>Statistics of the State of Massachusetts by Counties from the Federal Census of 1910.</caption>
<thead id="thead">
</thead>
</table>
var mass = [
{ County: 'Barnstable', Organization: 1685, Area: 409,
"Population 1910": 27542, "County Seat": 'Barnstable' },
{ County: 'Berkshire', Organization: 1761, Area: 966,
"Population 1910": 105259, "County Seat": 'Pittsfield' },
{ County: 'Bristol', Organization: 1685, Area: 567,
"Population 1910": 318573,
"County Seat": [ 'Fall River', 'New Bedford', 'Taunton' ] },
'....'
];
var massProperties = [ "County", "Organization", "Area", "Population 1910", "County Seat" ];
function generateCountyTable()
{
var tr = $('<tr>');
for (p = 0; p < massProperties.length; p++)
tr.append( $('<th>').text(massProperties[p]) );
$('#thead').append(tr);
var tbody = $('<tbody>');
for (county = 0; county < mass.length; county++)
{
tr = $('<tr>');
someplace = mass[county];
for (p = 0; p < massProperties.length - 1; p++)
tr.append( $('<td>').text(someplace[massProperties[p]]) );
// Last property is "County Seat", which could be an array or a single string
td = $('<td>');
var seats = someplace["County Seat"];
if (typeof(seats) == 'object') // array of towns
{
for (var seat = 0; seat < seats.length - 1; seat++)
{
td.append(document.createTextNode(seats[seat]));
td.append($('<br />'));
}
td.append(document.createTextNode(seats[seat]));
}
else // single town as a string
td.text(seats);
tr.append(td);
tbody.append(tr);
}
$('#thead').after(tbody);
}
Statistics of the State of Massachusetts by Counties from the Federal Census of 1910.
The steps in applying jQuery are:
- The code
var row = $('<tr>');creates a document fragment that is a<tr>element. - The code
$('<th>').text(massProperties[p])creates a<th>element that is a column header containing one of the property names, which is then appended to the<tr>element withrow.append( ). - Once the document fragment is complete, it is made a child element of the element
<thead id="thead">with$('#thead').append(row);. - The body of the table is created as a fragment with
var tbody = $('<tbody>');. - Each data row is then created as another fragment with
row = $('<tr>');and<td>elements are created and appended in the same way as for the head row. - As each row is completed it is appended with
tbody.append(row);. - Once all of the rows are appended to the
<tbody>element, the latter is added after the<thead>element.
The difference between append() and after() is that the former adds a child element to the selected element at the end of all other child elements, while the latter inserts a sibling element that is immediately following the selected element.
Note the typeof() function, which will return a value that can distinguish between different data types. In this case, if the result is "object" then it’s an array of strings that is joined together with a <br /> element, otherwise it’s a single string.
Summary
- The Document Object Model provides a large set of properties and methods that let you both read and modify the details of your Web page on the fly.
- The programming library jQuery makes it much easier to make these changes by providing convenient selection methods and easier-to-use tools for modifying the DOM.
Exercises
The gne.html document has four images other than the map tiles, which are written in place with HTML. Using jQuery, instead create and insert the four image elements into the document after the page has loaded, i.e. put the script at the end of the document and reference earlier positions. Hint: add id attributes to the elements where you want the images to end up.